深度学习框架caffe在ubuntu上无GUP编译环境详细配置
最近公司打算做人工智能方面,我这个什么也不懂的菜鸟就被推出来扛起大旗,在网上随便找了个贴子来安装caffe,没想到这一安装步步为坑,太多泪了
现在把详细的踩坑过程记录一下,以供后来人参考:
配置环境:Ubuntu14.041、先下载caffe源码,在https://github.com/BVLC/caffe直接下载还是用wget下载都可以。
2、解压后会看到里面既有Cmakelist文件和Makefile,Makefile.config用make直接编译和cmake都是可以的,两种方式我都测试了,下面讲一下直接make的方式。
3、先做准备工作安装依赖库,打开caffe的官方安装文档http://caffe.berkeleyvision.org/install_apt.html,其实直接用官方的东西是最好的,还是少搜贴子了,
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
由于是Ubuntu14.04的还要加几个包sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
4、注意注意 这里安装完的opencv版本应该是2.7的,很关键后面会用到。要以用 pkg-config --modversion opencv查看一下版本5、准备Makefile的配置文件,目录下本身就有个例子我们改改就可以了cp -rf Makefile.config.example Makefile.config,打开 Makefile.config
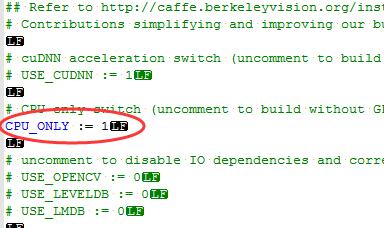
打开这个选项,只用CPU编译,由于先前安了好久的cuda都装不上,可能是我的机器显卡有问题,都快崩溃了,后来果断放弃改用cpu
6、有的地方好像还用atlas我也忘了,反正先装上吧sudo apt-get install libatlas-base-dev
7、然后直接make -j4
8、由于以前自己还安装了opencv3.6的库,这下出了很大的麻烦,caffe默认去找了3.6的库,这样就会出现找不到libIlmImf.so的情况,新的opencv3.6是不带so文件的,有三种方法可以解决
1.将新版本卸载,2.采用opencv版本切换这个可以网上搜一下很用弄,3.将旧版本的库复制到新版本的目录下,旧版本是/usr/lib/下,新版本是在/usr/local/lib下
9、这次再重新编译有的会出现
undefined reference to `cv::imencode(cv::String const&, cv::_InputArray const&, std::vector<unsigned char, std::allocator<unsigned char> >&, std::vector<int, std::allocator<int> > const&)' .build_release/lib/libcaffe.so: undefined reference to `cv::imdecode(cv::_InputArray const&, int)' .build_release/lib/libcaffe.so: undefined reference to `cv::imread(cv::String const&, int) |
这种情况应该是库没有链接到,这个是采用网上找的方法,将opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs加到LIBRARIES下,
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5 opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs |
10、顺利编译成功,有点小兴奋唉。。。
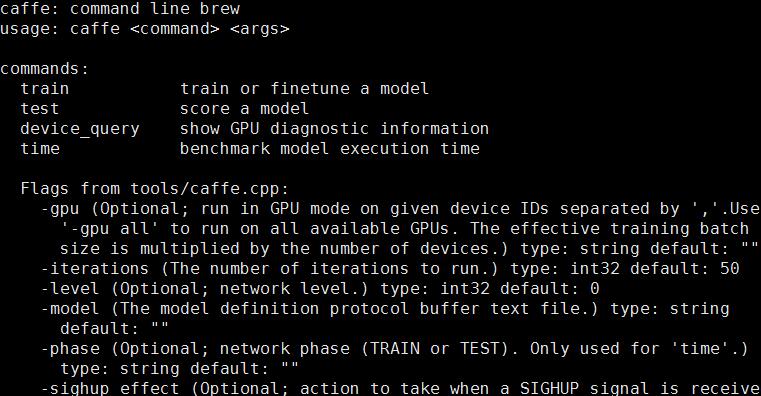
11、进入cd build/tools/,下面应该有个caffe的可执行文件,运行一下试试会弹出这么一坨,基本已经安装成功了。
12、因为下面的例子一般都是python的还需要安装一下python库,
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev |
14、我们测试一下识别图片的小例子吧,回到根目录下有个scripts目录,
./scripts/download_model_binary.py models/bvlc_reference_caffenet |
15、接下来下载对应的标签文件
./data/ilsvrc12/get_ilsvrc_aux.sh |
16、在网上随便下载了图片,放在了examples/images/dada.jpg

运行模型进行检测
./build/examples/cpp_classification/classification.bin \ models/bvlc_reference_caffenet/deploy.prototxt \ models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel \ data/ilsvrc12/imagenet_mean.binaryproto \ data/ilsvrc12/synset_words.txt \ examples/images/dada.jpg |
看见输出结果显示
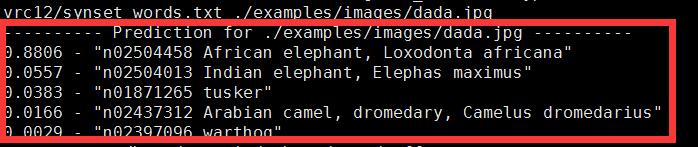
88%的概率是非洲象,这个区分的还是很细的,自己也可以下载一下大牛的模型自己试试哦,后面也会传一些自己训练的模型上来
有什么不明白的给我留言。

